Lecture 13
More instruction-level parallelism. Multiple issue and out-of-order execution.
Lecture
Outline
- Multiple issue processors
- Dynamic and static scheduling
- Out-of-order execution
Examples
| CPU Model | Microarchitecture | Generation | Issue Width |
| Core i7-3615QM | Ivy Bridge | 3rd Gen | 4 |
| Core i7-8665U | Whiskey Lake | 8th Gen | 4 |
| Core i7-1260P | Golden Cove (P-core) | 12th Gen | 6 |
| Gracemont (E-core) | 5 | ||
| Core i7-13700 | Raptor Cove (P-core) | 13th Gen | 6 |
| Gracemont (E-core) | 5 |
Workshop
Outline
- Experimenting with a 6-stage dual-issue RISC-V processor (use Ripes simulator)
- Experimenting with branch prediction (use RARS simulator)
Dual-Issue RISC-V CPU (Ripes Simulator)
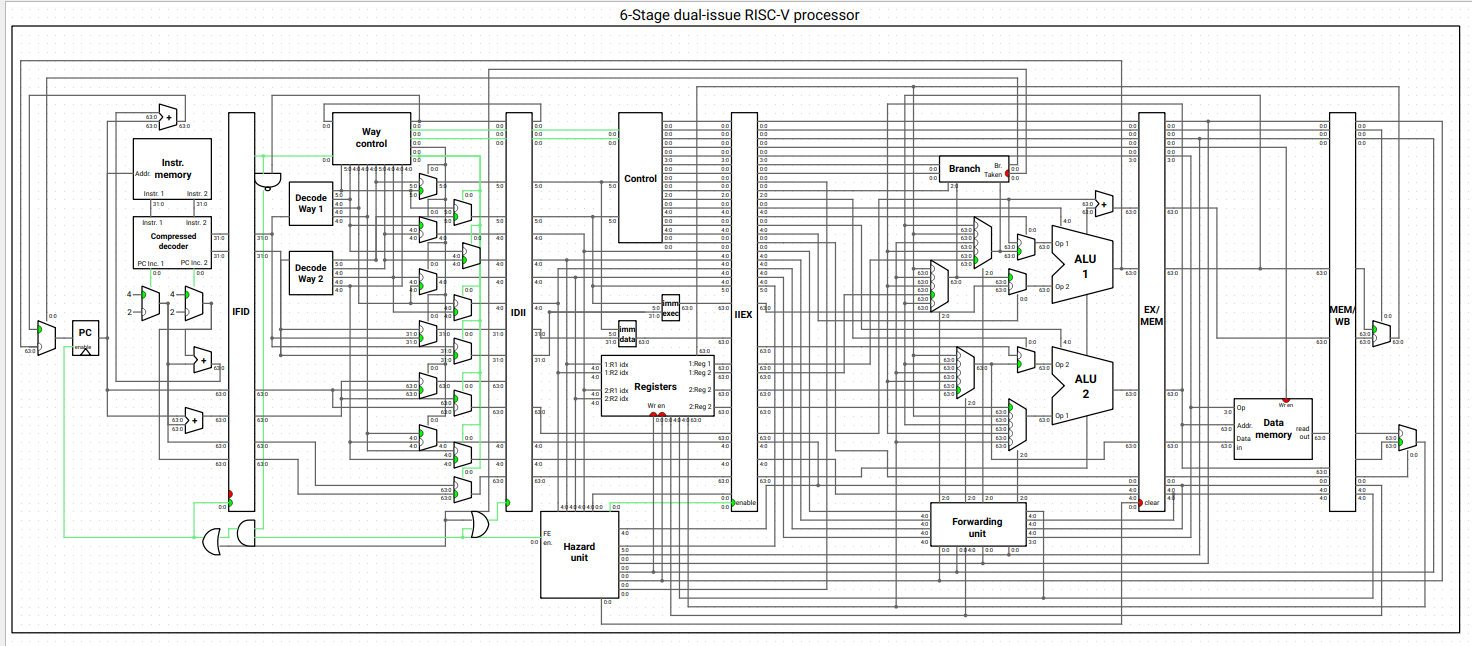
Examples
Runs the add_scalar.s example and see how many CPU clock cycles it uses.
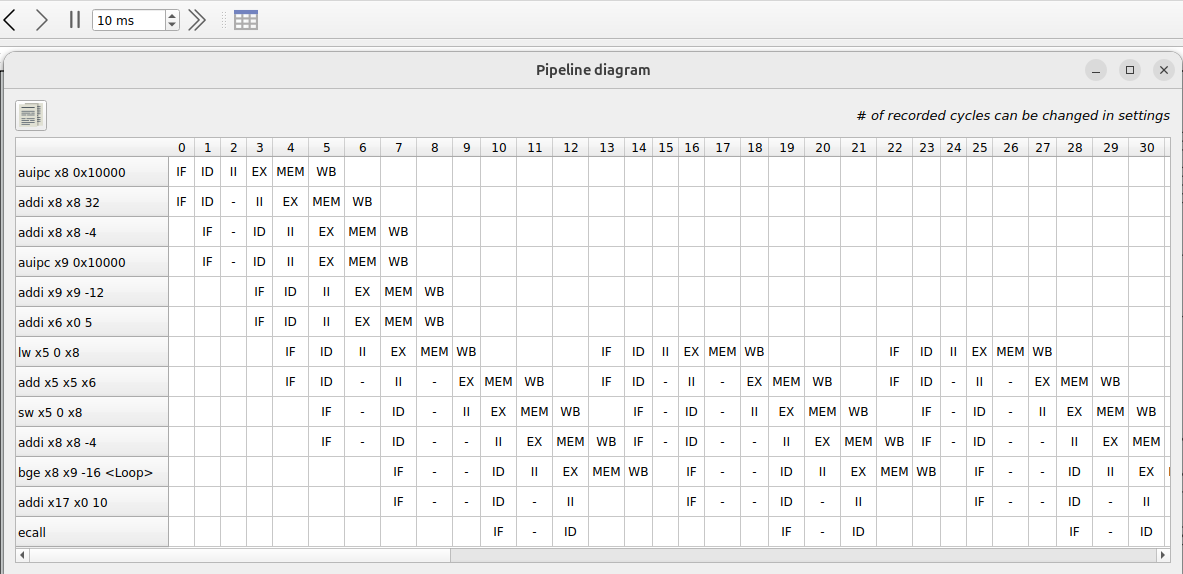
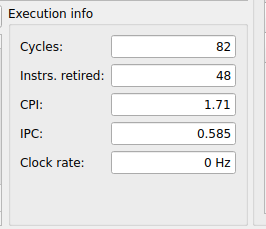
Branch History Table (RARS Simulator)
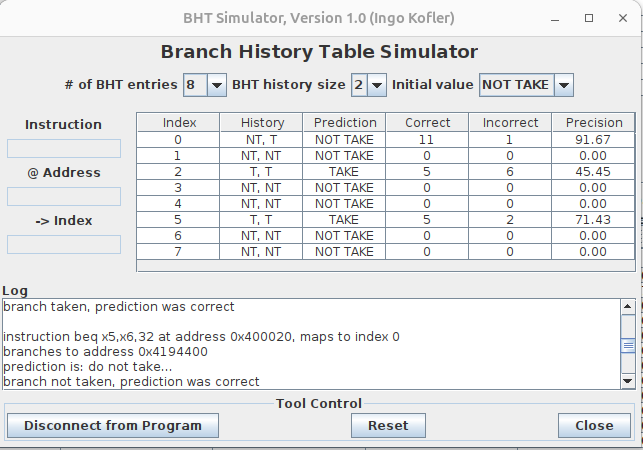
Run programs from lectures 4-7 in RARS simulator with the “Branch History Table” plugin connected. See how well it can predict branch outcomes with different settings.
Tasks
-
Optimize the add_scalar.s program to make it waste less CPU cycles. Use the loop-unrolling technique (two or more loop iterations merged). How many cycles are used now?
-
Write an optimized version of the PlusMinus program, which solves the issue of incorrect branch prediction with loop unrolling (“even” and “odd” operations must be done at the same loop iteration).
References
- Parallelism via Instructions. Section 4.10 in [CODR].
- Advanced Microarchitecture. Section 7.7 in [DDCA].
- Instruction-Level Parallelism and Its Exploitation. Chapter 3 in [CAQA] (Advanced).
- Instruction-Level Parallelism and Superscalar Processors. Chapter 18 in [COA].
- Superscalar processor (Wikipedia).
- Out-of-order execution (Wikipedia).
- Register renaming (Wikipedia).
- Branch predictor (Wikipedia).